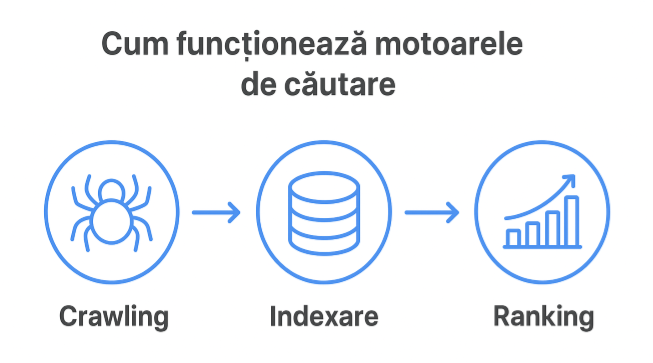
How Search Engines Work
To understand SEO, we first need to know how search engines work. Google and other engines crawl the web, collect information, and decide which pages to show and in what order for each query.
Crawling
The crawling process is how Google discovers new content on the internet. Search engines use automated programs called bots or spiders that navigate pages and follow links to find other pages.
- A bot visits
www.exemplu-pantofi.ro - Finds a page "Men's Sneakers" and adds it to the database
- Follows the link to "Elegant Shoes" and continues the process
Indexing
Once pages are discovered, they are indexed. This means they are analyzed and stored in Google's huge database.
- The text is analyzed to understand what the page is about.
- Elements like titles, subtitles, images, and meta descriptions are saved.
- If a page does not follow the rules (e.g., blocked by
robots.txtor marked withnoindex), it will not be indexed.
Ranking
Once indexed, pages need to be ranked for each search. Google's algorithms decide which page is the most relevant and authoritative for the user's query.
- Search for "men's sneakers" → Google decides if your page is better than competitors based on relevance and authority.
Important Google Algorithms
Google uses hundreds of factors and algorithms to determine a page's position. The most well-known are:
- PageRank — evaluates a page's authority based on incoming links.
- RankBrain — an AI-based algorithm that understands user intent.
- BERT — helps Google understand natural language and the context of a query.
Relevance vs. Authority
Two fundamental concepts in SEO are relevance and authority:
- Relevance = how well the page content matches the user's query.
- Authority = how trustworthy and popular the site is, often measured through quality external links.
Practical exercise: Think about our shoe website. How would you make a page about "women's sneakers" more relevant than the competitor's? What elements would you add to increase its authority?